
Nowadays becoming a value-driven organization is one of the top challenges of many teams and organizations. To fulfill this goal, storing vast amounts of data is a big challenge for both data scientists and data analysts.
Traditionally, data engineer teams who oversee data pipelines to store data cannot handle all the analytical questions of consumers. Most of the time they don’t have any information on the data and their focus lies on maintaining manual or automated ETL (extract, transform and load data) pipelines (see figure 1).
Here, we will provide an overview of an innovative approach called “data mesh” including its advantages and disadvantages as well as best practices for implementing a successful data mesh solution on the cloud.
Introduction to data mesh
The first thing you should know is that a data mesh is an abstract concept introduced in 2019 by Zhamak Dehghani (ex-director of emerging technologies for ThoughtWorks in North America), so the learning and discovering processes are still going on. That is why there is so much confusion as to what it is and what it is not. In her famous blog article she introduced the concept as follows:
Many enterprises are investing in their next generation data lake, with the hope of democratizing data at scale to provide business insights and ultimately make automated intelligent decisions. Data platforms based on the data lake architecture have common failure modes that lead to unfulfilled promises at scale. To address these failure modes, we need to shift from the centralized paradigm of a lake, or its predecessor data warehouse. We need to shift to a paradigm that draws from modern distributed architecture: considering domains as the first-class concern, applying platform thinking to create self-serve data infrastructure, and treating data as a product.- Zhamak Dehghani in How to Move Beyond a Monolithic Data Lake to a Distributed Data MeshData mesh is a framework to manage and organize data within an organization by dividing it into distinct business departments (or domains). It provides a way to decouple data services from the applications that use them, enabling each team to own and manage their data independently. The objective of the data mesh architect is to build a scalable, secure, and reliable data infrastructure in each domain that supports the needs of multiple applications. By employing this type of solution, businesses can benefit from increased efficiency when accessing or manipulating enormous amounts of data due to its decentralized nature. It also eliminates the need for complex ETL processes which often require manual steps and thus saves time while reducing errors associated with these processes.
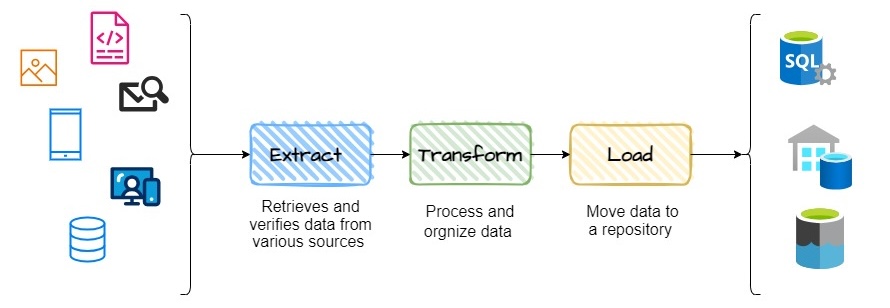
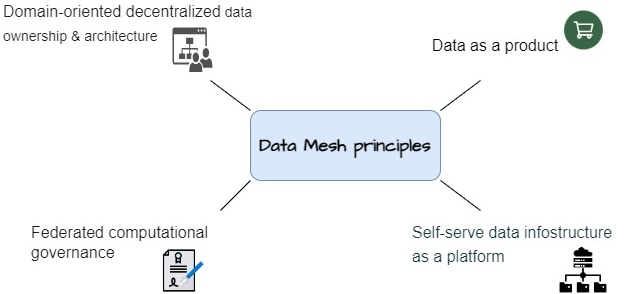
A schematic showing of ETL (Extract, Transform, and Load) pipeline, data is obtained from multiple sources, transformed, and stored in a single data warehouse, with access to data analysts, data scientists, and business analysts for data visualization and statistical analysis model building, forecasting, etc. Data mesh is built on four main principles: 1) domain ownership, 2) data as a product, 3) self-service data platform, and 4) federated computation governance. The first two principles accentuate an organizational mind shift to treat data as a product owned by individual teams. The second two principles focus on the elements of the technical foundation. Below we explain each term in more detail.
Principles of data mesh
As shown in figure 2, the 4-principles are:
- Domain ownership: Traditionally, data is hosted in a data warehouse (DWH) or data lake. DWH stores cleaned, aggregated, and structured data to build dashboards on top of that by data analyst but these data cannot be used by data scientist. Data scientists need to work with raw data which has all the information. A data lake – in a monolithic architecture – would be responsible for storing all raw data, and a single data team supervises managing the lake and data requests of business teams. One of the challenges of these traditional data ecosystems is that there is no real ownership of the data itself. Lack of data ownership leads to data quality and consistency issues and causes confusion about who is responsible for maintaining and updating the data. In the data mesh framework, each domain team (e.g., HR, marketing, sales, finance, accounting, etc.) handles the quality and consistency of the data that they own.
- Data as a product: The second principle treats data as a product rather than a by-product or just an asset of organization. This product thinking means that there are consumers for the data beyond the domain. Each domain team is responsible for providing high-quality data which can be solo or shared with other domains. The data mesh approach puts quality first and addresses the consumer’s requirements.
- Self-service data platform: A self-service data platform is a platform that allows the data teams to easily discover access and manage their stack in each domain. In this framework, there is one central platform with all the tools and services needed for computing, storage, and analyses of data irrespective of other domains, which are provided and managed by the data team. On the other hand, each domain has its specific infostructure to manage and to process the data product they build.
- Federated computational governance: The final principle aims to support all three principles mentioned above by applying governance on each domain. However, all domains still stand under one standard rule that the organization has decided upon globally.
Data mesh architecture is built upon 4 principles designed to address the challenges of scaling and managing data within and across organizations. Data mesh architecture
A data mesh solution is a decentralized approach that authorizes domain teams to perform cross domain analysis and respond quickly to business needs by adjusting on-the-fly with minimal disruption to other domains. In addition, due to a decentralized approach, data mesh is scalable (up or down) on demand without any interference on other data domains or products. One can scale up or down the number of domains or data volume easily. By separating individual datasets into distinct domains based on their purposes, a data mesh solution ensures that all relevant requirements are met at each stage of the process. This makes it easier for companies to keep regulatory compliance while still providing efficient access to the necessary information for decision-making purposes.
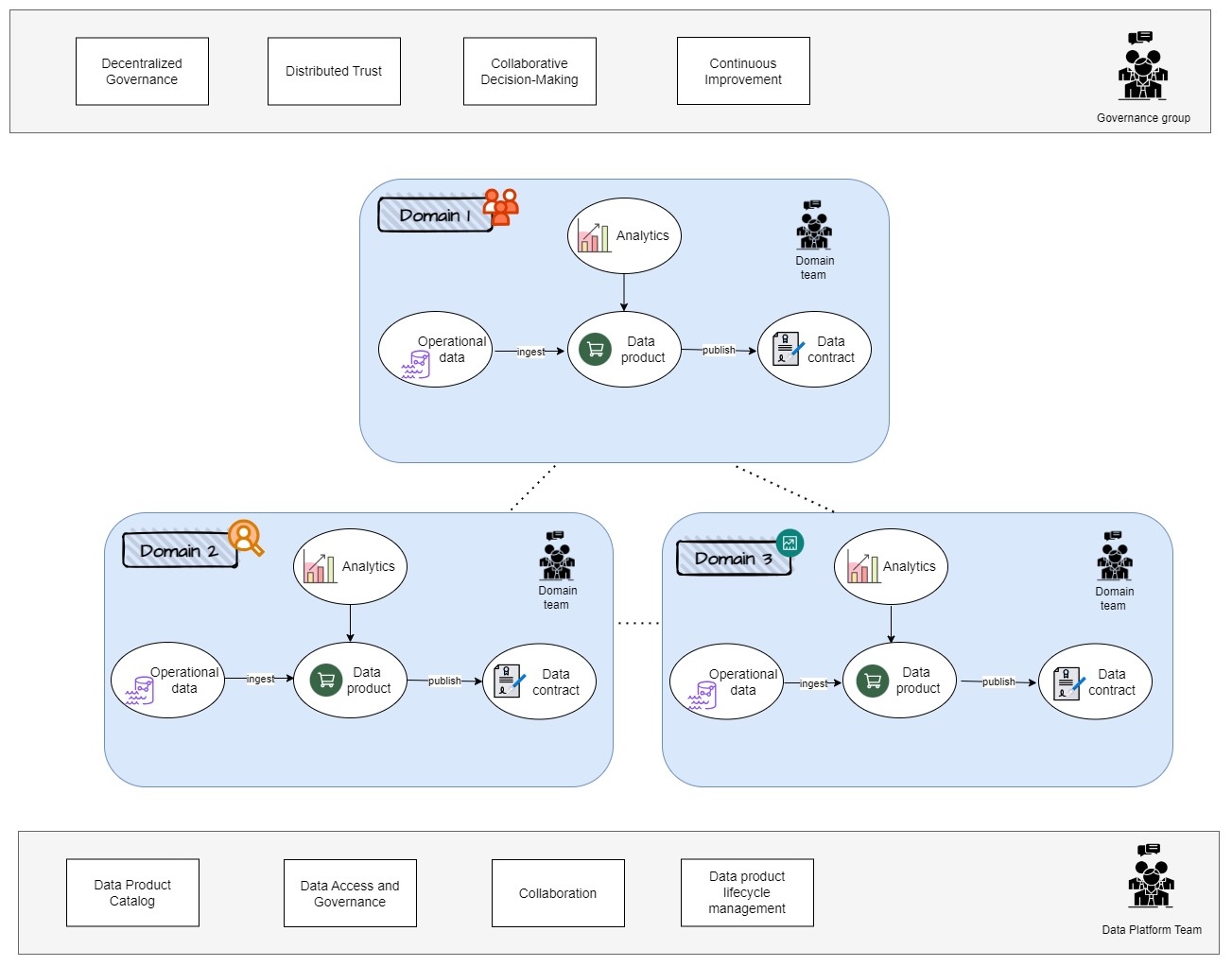
An example of domains architecture in data mesh. It is composed of three separate components: operational data in each domain, data infostructure and governance. Each domain team ingests operational data and builds analytical data models as data products to perform their own analysis. Data products may also serve other domains. Data governance ensures consistency, quality, and security of products across domains. Figure 3, is an example of 3-domains within the organization. For the sake of simplicity, imagine we have only sales, finance, and marketing domains. We call domain 1, “sales domain”. The sales domain will obviously have the sales team and the sales team will consist of the head of sales, different sales specialists, the data experts within the sales department etc. The domain team is also responsible for managing the domain’s data contract with other domains (organization’s operations). Each domain is going to be responsible for defining its own data needs and for building and supporting its own data products.
First, we have the operational data. The operational data is generated by the organization’s daily operations. All this operational data is fed into the data products. A data product is a product or even a service that is built around the data of the domain. In the context of data mesh, this can include anything from a dashboard that displays real-time data to a machine learning model that predicts future outcomes based on historical data. For example, a data product of sales domain could be a sales forecast for the next six months divided by the different regions and products representing some key metrics. Analytics is the process of using data to gain insights and make informed decisions. This will include things such as data mining, statistical analysis and even machine learning (ML). In the context of data mesh, each domain is responsible for defining its own analytics needs. This is important because the analysis, together with operational data, will make a data product.
Moreover, each domain has its own data contract. A data contract is a form of agreement between the data producers and data consumers. Consumers are typically internal, meaning other teams within the organization besides the team that owns the product.
A central data contract on top outlines how data can be exchanged between domains. It defines the structure, format, and rules of exchange in a distributed data architecture. These formal agreements make sure that there are no uncertainties or undocumented assumptions about data. In this example, the domain team owns the data and consumers will typically be, internally, the team owning the product and other teams within the organization.
In data mesh each domain is enabled to manage its own data and analytics in a decentralized and autonomous way. However, while still ensuring that the data is shared and integrated effectively across the organization. So, this is the central and most important part of data mesh architecture. One needs to create logical domains and identify what products will be created within these domains and then have an agreement to share these products with other domains within the organization.
Implementing data mesh step by step
To implement the data mesh architecture, there are several steps you must consider. It is worth mentioning that although many organizations are keen on implementing the data mesh architecture, it can be applied at some projects only. As an instance, organizations need to answer these questions before adding more complexity to the workflow, e.g., how big is your data set, how many data teams in your organization rely on your data, how many products does your company have, how many domains you have, and how many data-driven features are being built. If these are critical points which make sense for your company, then data mesh architecture is a wise solution for all data across the enterprise.
To just give an overview here is the list of steps:
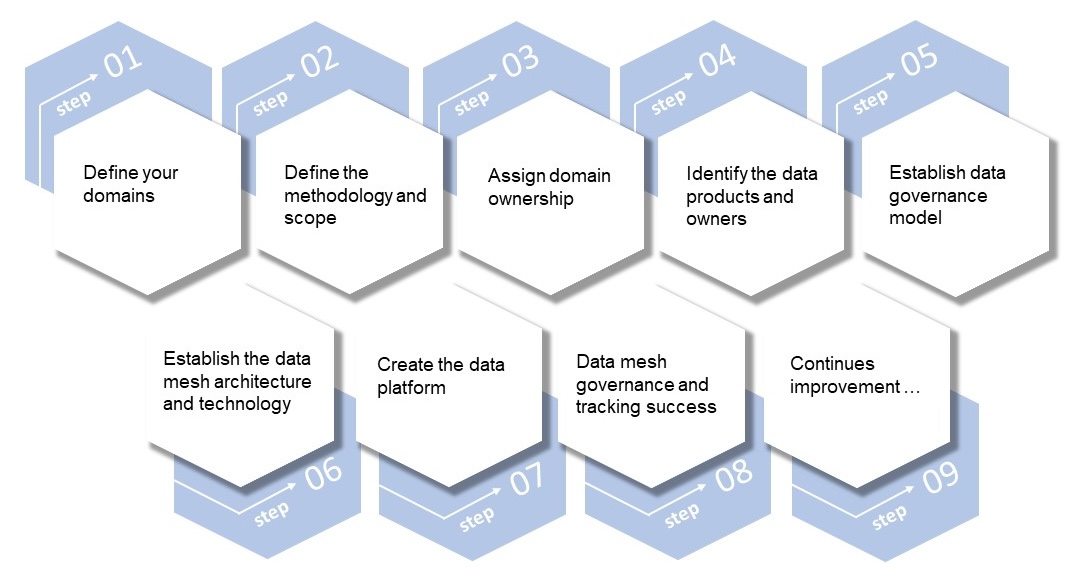
Implementing data mesh in an organization involves a comprehensive strategy that addresses both the technical and organizational aspects of data management. Here is a general overview of how to effectively implement data mesh. Step 1 Define your domains: A domain is a specific business capability or function within an organization. Each domain will have their own data from their day-to-day operations. In addition, they also have their own solutions. It really depends on the structure of your organization. Identifying all the domains within an organization is crucial, cause it’s going to help to understand the data needs of each domain and how these different domains are interconnected. Also defining the domains will give a clearer picture of how complex implementing data mesh is going to be and what kind of team an organization may need.
Step 2 Define the methodology and scope: This means one should identify the goals of implementing a data mesh in specific domains. One should set a priority list on what are the most important domains to implement on data mesh first, before you start expanding it to the other domains. You should also identify any constraints or limitations that could impact your implementation.
Step 3 Assign domain ownership: Assigning domain ownership for each domain to a specific team or, even better, specific people within the team, is important to ensure that the accountability and responsibility for the data domain and its data products is clear from the start. This will also help ensure you have the right people responsible for the data assigned to the domain.
Step 4 Identify the data products and owners: Next, one should identify data products and owners in each domain. So here with the example of sales domain, you should have a look at all the different data products that are critical for the success of the domain, but not only of the domain where they reside, but the success of other domains. So, let us say, for example, under the sales domain, one of the key data products is going to be a forecasting solution where we are forecasting the sales across the company via the different verticals, such as products go-to-market types, regions, countries etc. In step four, you should identify all the different data products within each domain that is in scope for implementing data mesh and then have a clear ownership for all these data products assigned. In addition, you can identify any additional data products that can be created later. This will help you ensure that each domain has the necessary data products to meet its business needs and that the right people are managing these products.
Step 5 Establish the data governance model: Once different domains and the ownership of the products within the domains is defined, it is time to establish the data governance model. Data governance is critical to the success of implementing data mesh. In this step, one needs to spend some time to define how data governance will work within the data mesh environment. In this step, we also define all the different data policies, standards and other processes for data quality management, data security and compliance that will be needed going forward. This is one of the most complex steps.
Step 6 Establish the data mesh architecture and technology: In this step, you need to establish the data mesh architecture and technologies that will be used. Here, you need the best technical experts within your company to take part in establishing things such as what data platform is going to be used, what APIs will be used to manage the exchange of data between the domains. It should also establish guidelines for data modeling, data integration and data exchange to ensure consistency across the domains.
Step 7 Create the data platform: Here you need to create the foundations for your product catalog and the different processes for data validation, data transformation and data enrichment to ensure data quality and consistency. This is where your technical team will need to get down to business and start creating an actual data platform that can be used by the different domains.
Step 8 Data mesh governance and tracking success: Once we have our data mesh up and running, we need to establish some processes for the governance, how are we going to track how successful our data mesh implementation is? You need to put some controls in place to monitor the data quality, ensure compliance and track some key performance indicators, KPIs, to measure the effectiveness of our data mesh. This step will also make it possible to report to the senior leadership in the company.
Step 9 Continues improvement: Continuous improvement will usually be based on feedback from the different domains. The data mesh program team will usually receive ideas, escalation complaints or positive feedback from the different domains on specific parts of the data mesh environment. For example, the team is not going to like the data product catalog because the search function does not work properly. When you receive this kind of feedback from the different domain teams, you need to put down all the different ideas, complaints, and escalations on a list. Then you start prioritizing what’s going to be important to improve or what is going to make sense in terms of a return on investment, because improving some things may not be a good return on investment in terms of how much time and effort is going to take.
Solutions for Implementing data mesh on the cloud
To read further, here we mention two example solutions for implementing serverless data mesh on AWS and Azure. However, here we only discuss one solution using AWS services.
High Level Architecture on AWS
As shown in figure 5, this architecture separates consumers, producers, and central governance domains. Expanding on the preceding diagram, we provide additional details to show how AWS services support producers, consumers, and governance. Each data domain (Data account Org 1/2/3), whether it is a producer, consumer, or both, is responsible for its own technology stack. These stacks can be independent from each other yet can be shared between other domains, and this ensures cloud costs remain low.
The producer domain may build different pipeline orchestration using Spark, Glue, Step Functions, Lambda, etc. Also, consumers in one domain based on their needs may employ Jupiter tool to analyze data where another domain applies BI report tools to visualize data.
A producer domain resides in an AWS account and uses Amazon Simple Storage Service (Amazon S3) buckets to store raw and transformed data. It should be noted that domains can use different storage services like data lake or data warehouse. In this simplified example all domains use S3 to store their data.
Each data domain maintains its own ETL stack using AWS Glue, EMR, … to process and prepare data before being cataloged into a Lake Formation Data Catalog in the respective account. Similarly, the consumer domain includes its own set of tools to perform analytics and ML in a separate AWS account. The central data governance account is used to share datasets securely between producers and consumers. It’s important to note that sharing is done through metadata linking alone. The central catalog makes it easy for users to find data and to ask the data owner for access to a specific place.
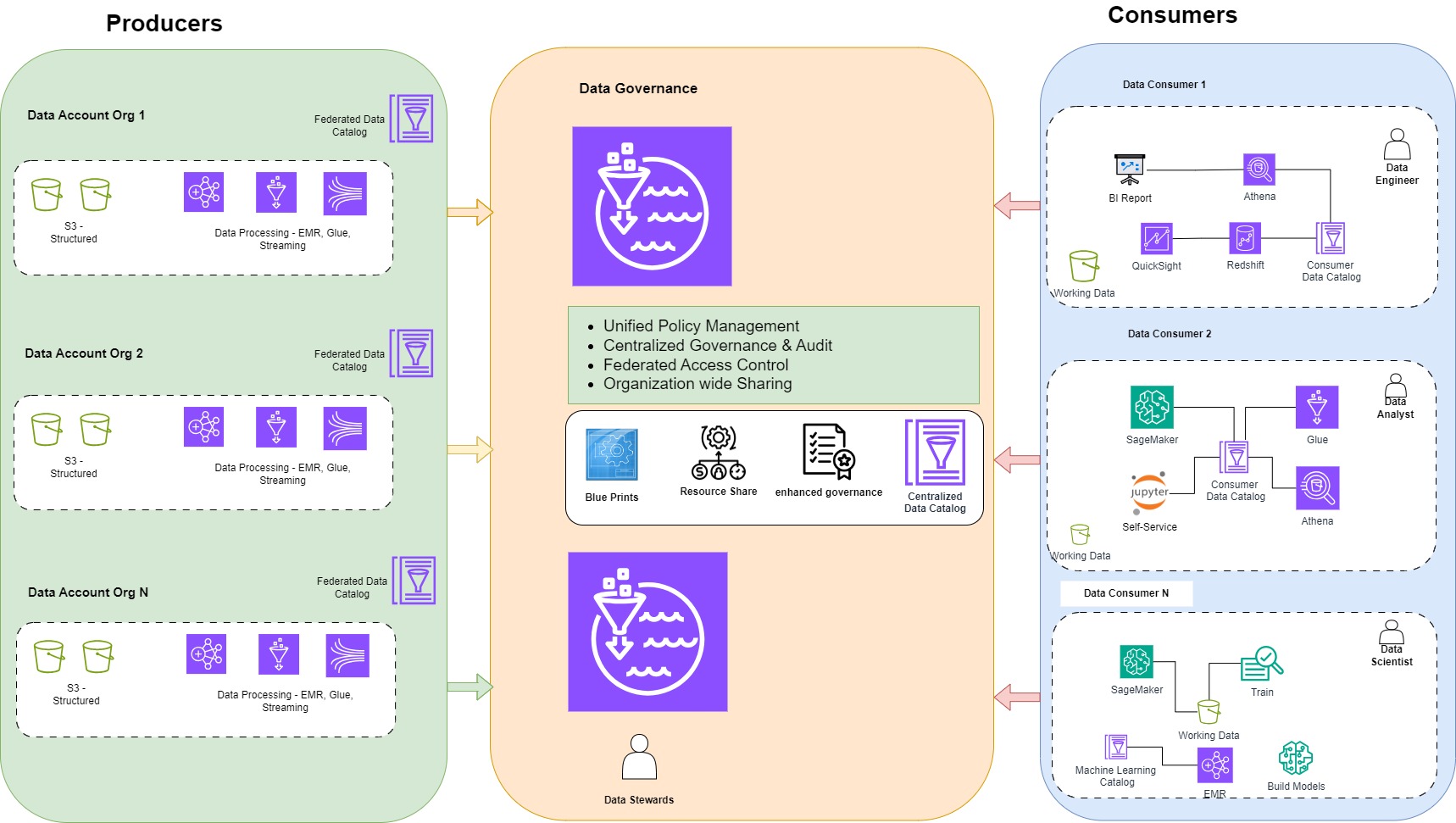
High-level overview of data mesh architecture on AWS by using different serverless tools. In summary
Data mesh is not just a better paradigm than data warehouse or Data Lake. It is indeed another decentralized way to design and manage data within an ecosystem. A well-organized and well-managed data warehouse or data lake can provide significant value, especially for organizations with specific use patterns and use cases. The selection between data mesh and traditional data architectures depends on the specific needs, capabilities, and goals of the business. Data mesh increases agility and scalability, as well as improved data quality and better alignment between business and technical team. By distributing data ownership and responsibility across different domains, data mesh can enable faster and more efficient data processing and analysis. Proper planning and implementation of data mesh is challenging e.g., identify and define domains, define tagging, establish data governance in each domain and cross domains, and setting up the necessary technical infrastructure and tools to support the distributed data architecture.
Each approach has its strengths and drawbacks, and what works best varies from context to context. Data mesh is a modern analytics architecture targeted at mid-sized and large organizations with Big data set, which means that small organizations with small teams and small number of data producers/consumers will most likely not benefit as much from it. Building a data mesh can be time consuming, as it requires a thorough understanding of the organization’s data landscape and a careful design and implementation process.
Credits
Title image by Jie Wang 127 on Shutterstock

