
Structure of this Blog
At the start we have an introduction as to what Data-Oriented Design (DOD) is used for, what the problem with current popular paradigms in the business space is and how we can solve them with DOD. This is followed by a technical section that will explain some of the concepts of DOD with examples. At the end, I will show the usage of ECS and list some frameworks.
Introduction
DOD was used a decade ago predominantly by the video game industry. Back when a complex game had to fit on something like a 32MB cartridge. Humans had to find ways to think more like a computer to make data fit and make their programs run more efficient.
The Problem with current Paradigms
With computers becoming more powerful we had to concern ourselves less and less with performance. So we slowly moved to less efficient and easier to read/write ways of programming. However, by paying less attention to performance we are required to invest more money into hardware. It is not really significant for a small app, but at enterprise scale - where massive amounts of datasets need to be processed every second with an extra layer of redundancy - costs explode.
What is DOD?
Data-Oriented Design is more of top-level paradigm on the level of OOP/Functional Programming that makes data a first-class citizen.
ECS or Entity Component System is a macroarchitectural pattern that lives in the DOD world.
SoA or Struct of Array is an example of a microarchitectural DOD pattern.
How can it solve our Problem?
Now as with any other top-level paradigm we can extract parts of it and use it where it yields us the most benefit. If used correctly, ECS can improve performance up to 100x. You can find an example of performance increase in this video by Nomans Skywalker on YouTube.
In my opinion, DOD shows its best side when it is used in a message-driven/stream architecture, because the ECS pattern feels most natural with data streams. By implementing it that way, it allows us to implement an ECS compute service into existing software which could reduce our compute demand by up to 100x, which in return reduces costs and scales better.
As an example we could implement an MQTT interface into existing software, that sends a very compact SoA block of data to our ECS microservice to compute and after it is done it returns the chunk of computed data. A messaging service also makes it very easy to scale up the ECS microservices even across multiple devices.
Concepts of DOD
Array of Struct (AoS) vs Struct of Array (SoA)
SoA over AoS is a core concept of DOD and is responsible to structure data efficiently on CPU or memory to process it faster and more efficient.
AoS is commonly used in OOP and looks like this:
class Person{
string name;
int age;
...
}
class Foo{
List<Person> personList;
}
SoA looks like this:
struct People{
string[] names;
int[] ages;
...
}
(There is also AoSoA, which combines both paradigms to slice the data into chunks that fit the SIMD vector size.)
Now imagine we want to iterate over all the names. This would look something like this in the CPU:
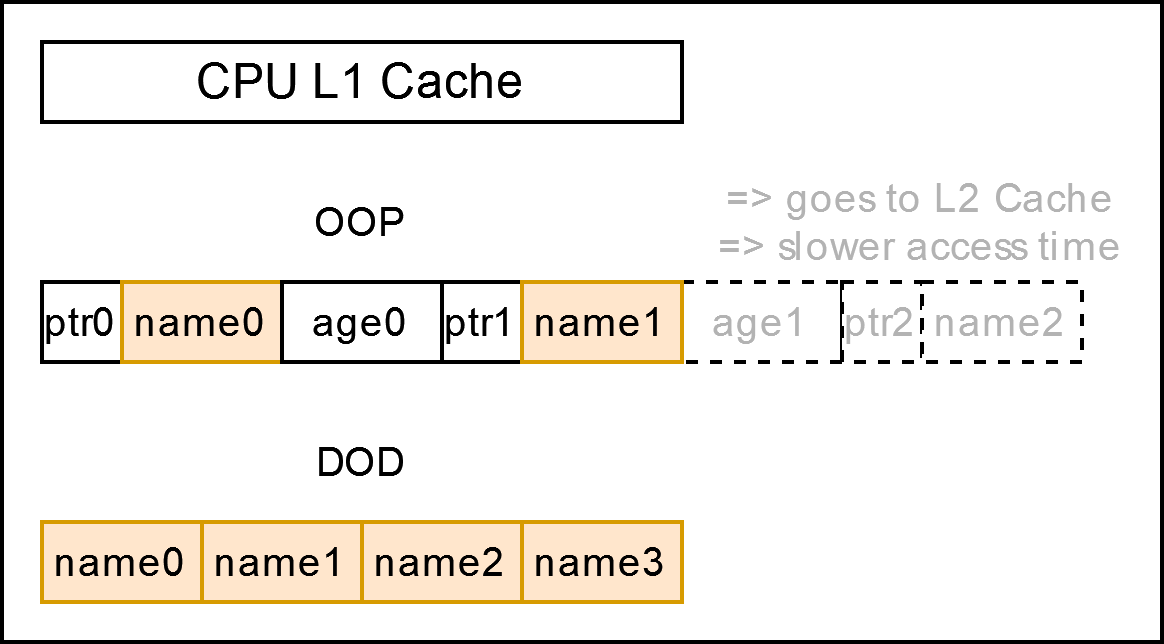
As you can see the DOD approach gets rid of unneeded overhead.
Data Locality
The closer the data is to your CPU, the faster it can be accessed. I have put together a table with the levels of storage including the size and approximate access time (Source).
| Label | Size | access time |
|---|---|---|
| L1 Cache | 512KB | 1ns |
| L2 Cache | 4MB | 4ns |
| L3 Cache | 32MB | 20ns |
| Memory | 32GB | 100ns |
| SSD Storage | 1TB | 16000ns |
As you can see, the access time changes drastically depending on where the data is located. Therefore we want to optimize the usage of L1 and L2 cache.
“Bottom Up” Query
With the term “bottom up” query, I am referring to the process of accessing data from bottom to top rather than from top to bottom. This approach allows us to structure our data differently and in my experience it works better when dealing with data arranged in columns.
Let’s consider an example where we have a populated data collection of employees and we want to query for employees named “Hans”:
Top Down:
employees //rows of employees
.Where(employee => employee.firstname == "Hans");
Bottom Up:
firstnames //column of names
.Of<Employee>() //further reduction of dataset by flag
.Where(firstname => firstname == "Hans") //get indices
.Fetch<Employee>(); //fetch employees
In the first case we iterate over all the employees and open them up looking for those named “Hans”. In the second case we only retrieve the column firstnames and, before we iterate, we eliminate all rows that are not of type Employee.
Keeping Data Dumb
Early on in OOP and Domain-Driven Design (DDD) we learn that we should validate our data as close as possible to the data-object to restrict other developers from instantiating invalid objects. This means that in C# you will sometimes see code like this:
public class Person{
private string firstname;
...
public string Firstname{
get{
return firstname;
}
set{
if (string.IsNullOrEmpty(value)) {
throw new ArgumentNullException(
$"{nameof(Employee)}.{nameof(Firstname)} cannot be null or empty");
return;
}
firstname = value;
}
}
...
}
public class Employee : Person{
...
}
public class SomewhereElse{
public void Foo(){
Logger.LogInfo("Starting program...")
...
List<string> nameList = new List<string>();
//populate nameList from a csv
var employeeList = new List<Employee>();
foreach (string name in nameList){
try{
employeeList.Add(
new Employee{
Firstname = name
}
);
Logger.LogInfo($"Person {name} was successfully read.")
}
catch(Exception e) {
Logger.LogWarning(e.StackTrace);
}
}
//write to DB and handle DB error
Logger.LogInfo("Employees were written to DB.")
...
Logger.LogInfo("Stopping program")
}
}
I have come across code like this several times and there are lots of points we can improve upon:
- throwing an exception → an exception is an interrupt, which means the thread will stop whatever else it is doing and build&throw the exception first
- logging → logging could be its own topic, but two short pointers here: clear and short messages (stop logging stack traces, please); only log what you will read
- inheritance → inheritance is considered bad practice and we want to use composition wherever possible instead
- mutable object → an employee is a rather static object and won’t change a lot in the flow of a program. Making it read-only will yield up to 2x performance
- constructor → using an empty constructor here also breaks the upside of DDD principles, because it allows us to create an invalid
Employee. - sealed class → sealed classes will restrict the object from being further inherited from and yields vast performance increases (credit to Nick Chapsas YT here: https://youtu.be/d76WWAD99Yo)
- using
Listeverywhere → one could argue that it is ok in this context, but I have also seen Senior Developers only working withLists instead of using the correct Data Collection for the job, because they feel most comfortable withLists.
public readonly struct Person{
public readonly string Firstname;
...
public Person(string firstname){
Firstname = firstname;
}
}
public readonly struct Employee{
public readonly Person Person;
...
public Employee(Person person){
Person = person;
}
}
public class SomewhereElse {
public void Foo() {
IEnumerable<string> nameList;
//populate nameList from a csv
var employeeList = new List<Employee>();
int errorCount = 0;
foreach (string name in nameList) {
if (string.IsNullOrEmpty(name)) {
errorCount++;
continue; //jumps to next name in list
}
var person = new Person(name);
employeeList.Add(new Employee(person));
}
if (employeeList.Any()) {
//write to DB and handle DB error
Logger.LogInfo($"Operation succeeded. {employeeList.Count()} employees were successfully written and {errorCount} could not be written");
return;
}
Logger.LogError($"No valid employees to be written. {errorCount} invalid employee lines.");
}
}
You can see that the second example already has a much calmer flow to it.
Summary
Up to this point I tried to highlight DOD concepts that are also partially incorporated in modern best practices which are reflected in recent language changes, especially in C#. Now the key concepts of DOD I take into everyday programming are:
- use value types wherever possible
- use the correct collections for the right job
- reduce boxing and/or inheritance wherever possible (use interfaces and pure functions over inheritance)
- to compute large amounts of datasets, try to work with chunks and keep the data separate from business logic
- know how your computer works. For C# there is sharplab.io where you can view your code as IL or JIT asm. Also don’t be scared to run benchmarks.
We also try to incorporate the main two concepts of functional programming, because many consider them best practice for most programming approaches. Those are:
- immutability
- pure functions
All of this also goes hand in hand with my preferred test strategy, which is Test-Driven Development. However, I just write unit tests and do not mock anything.
An in-depth discussion of modern best practices is certainly worth several articles by itself.
Entity Component System - ECS
ECS will be less practical for the average programmer, since you probably won’t start writing your own ECS framework/language or will not be working with it in the near future. However, it employs very interesting concepts and tackles the following tradeoff problem:
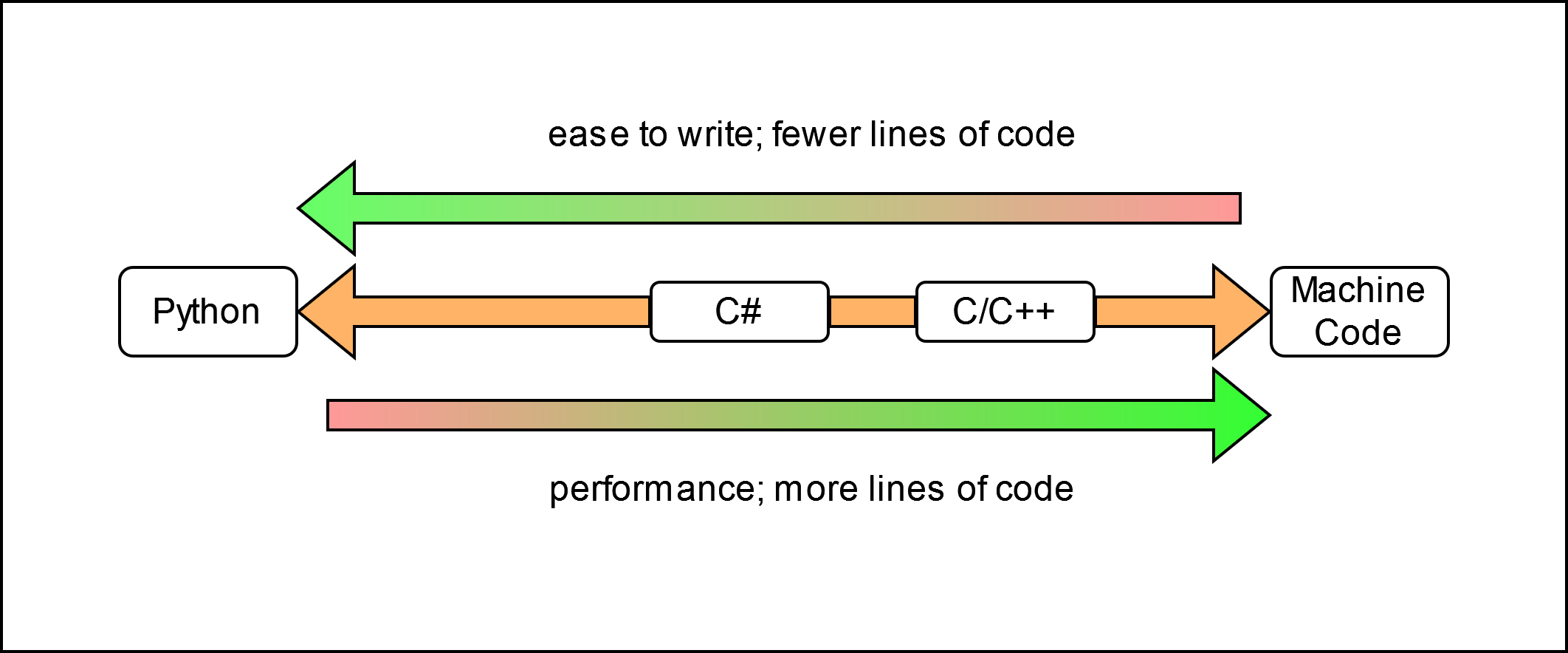
In this diagram, we can see that most of our languages must sacrifice either major parts of readability or performance.
Entity Component System is an architectural pattern that brings all the benefits of DOD together and wraps it into readable and easy to write code. Therefore increasing performance AND readability. It consists, as the name suggests, of 3 (sometimes 4 or more) major parts. ECS is written as “Entity Component System”, but it makes more sense to picture it as “Entities, Components, Systems”. Because these parts are all seperate patterns, but together they form a cohesive architecture:
- Entities - are indices that point to its components → forming a composition
- Components - are the raw data components
- Systems - are behaviours that change components → functions
- (Archetypes - this is a composition indexer of components that acts as a template to create/query entities)
These parts are most of the time handled by a manager class. These manager classes give the ECS parts its purpose:
- EntityManager - handles indexing and instantiation of entities and its data
- ComponentManager - basically a column-based dataengine
- SystemManager - computes components; responsible to manage the order of systems
You can think of these managers of what would be built into the programming language itself, if there was an ECS programming language.
Now let’s see what ECS can look like in use:
Components
public struct PositionComponent{
public int x, y, z;
}
public struct MovementComponent{
public int x, y, z;
}
These 2 get constantly updated, so we refrain from immutability this time.
Archetype
I included it here to give you an idea of what archetypes are typically used for. You can see the usage of it in the entities and systems section.
public readonly struct Archetype {
public readonly Type[] componentTypes;
public Archetype(params Type[] componentTypes) {
this.componentTypes = componentTypes;
}
}
Entities
Since entities are just pointers usually held by the EntityManager, I just display an example instantiation of entities here.
EntityManager em = new EntityManager();
List<PositionComponent> playerPositions = new();
List<MovementComponent> playerMovement = new();
Archetype personArchetype = new Archetype(typeof(PositionComponent), typeof(MovementComponent));
for (int i = 0; i < 100000; i++) {
playerPositions.Add(new PositionComponent(i,i,i));
playerMovement.Add(MovementComponent.Random());
}
em.CreateEntities(personArchetype, playerPositions, playerMovement);
Systems
//with Archetypes
public static void MovementSystem(Entities entities){
entities
.Of(personArchetype)
.ForEach((ref PositionComponent pos, in MovementComponent move)
=> {
pos += move;
}
)
.Schedule();
}
//without Archetypes
public static void MovementSystem(Entities entities){
entities
.With<MovementComponent>() //also .WithOut<>()
.With(typeof(PositionComponent))
.ForEach((ref PositionComponent pos, in MovementComponent move)
=> {
pos += move;
}
)
.ScheduleParallel();
}
This is the gist of ECS.
I have gathered a list here of 13 ECS frameworks spanning all kinds of languages:
- Unity (C#)
- C/C++
- C#
- Rust
- Python
- Kotlin
- Fleks (created by a colleague at NTT DATA, Simon Klausner :D)
- Lists by other people
My work with Unity DOTS or Data-Oriented Tech Stack in the past is what first triggered my passion for DOD and ECS. I am currently planning my own ECS programming language, doing benchmarks and everything, which is also why I wanted to share some useful insights that I gained on my journey so far.
I hope that you are able to take away something from this and I think you are now deserving a relaxing break after this read :D
Credits
Title image by rybarmarekk on Shutterstock
